Apache Solr: Bir Arama Motorundan Fazlası
3 Ağustos 2017 Zafer Ayan NoSQL 1 yorum
Apache Solr — Görsel: apache.org
Geçtiğimiz haftalarda ElasticSearch ile ilgili bir yazı yayınlamıştık. Apache Solr da benzer bir göreve sahip olup, temel olarak gücünü indeksleme mekanizması sağlayan bir Java kütüphanesi olan Apache Lucene‘den alan açık kaynaklı bir arama platformudur diyebiliriz. Temelinde arama motoru olmasına rağmen verilerin replikasyonu ve çoklu core’lara izin vermesi gibi birçok özelliğiyle bir arama motorundan daha fazlasını sunar. Solr aynı zamanda HTTP istekleriyle sorgular yapabileceğiniz kur-çalıştır mantığında kullanıma hazır bir web uygulamasıdır. Bu özelliğiyle Lucene’in paketlenmiş bir hali gibi düşünebilirsiniz.
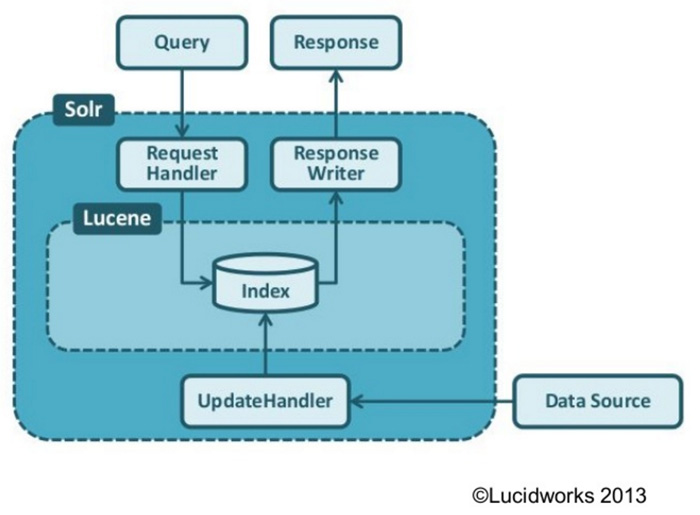
Apache Solr Mimarisi — Görsel: slideshare.net
Öncelikle Solr’ı çalıştırabilmek için 8GB veya daha üstü bir RAM’e sahip bir bilgisayara ihtiyacınız var. Yoksa Azure veya Amazon üzerinden instance oluşturarak da kurulumu gerçekleştirebilirsiniz. Solr’ı resmî sitesinden temin etmenize ek olarak Java version 8‘in de sisteminizde kurulu olması gerekmektedir.
Sisteminizdeki yüklü Java sürümünü kontrol edebilmek için:
java -version
komutunu çalıştırabilirsiniz.
Solr’ı indirip ilgili arşivi C:\ dizinine çıkardıktan sonra aşağıdaki komutu yazarak gettingstarted adındaki halihazırda yüklü örnek koleksiyonun 2 node üzerinden çalışmasını sağlayabilirsiniz:
solr start -e cloud -noprompt

Üstteki komut çalışmasını tamamladığında Solr uygulamamızın yönetim paneli localhost üzerinden hizmet veriyor olacaktır. Yönetim paneli ile ilgili kısma yazının ilerleyen kısımlarında değineceğiz.
Apache Solr yönetim paneli
Dokümanlar ve Koleksiyonlar
Solr, doküman temelli bir veritabanıdır. Person gibi veritabanı varlıkları isim, adres ve email gibi alanlardan oluşabilir. Bu dokümanlar ise koleksiyonlarda saklanırlar. Koleksiyonları, geleneksel veritabanlarındaki tablolar gibi düşünebiliriz. Tek ve en önemli fark, geleneksel veritabanlarının aksine bir “Person” varlığı, birden fazla adres bilgisini aynı dokümanda barındırabilir. Geleneksel veritabanında ise Adres adında yeni bir tablo açıp “Person” ile ilgili ilişkiyi sağlamak gerekir. Örnek bir Person dokümanı aşağıdaki şekilde oluşturulabilir:
Person {
"Id": "1333425",
"first_name": "Francis",
"middle_name": "J.",
"last_name": "Underwood",
"address": ["1600 Pennsylvania Ave NW, Washington, DC 20500", "1609 Far St. NW, Washington, D.C., 20036"],
"phone": ["202-456-1111", "202-456-1414"]
}
Shard, Replica ve Core Nedir?
Birçok ilişkisel veritabanın aksine veriler otomatik olarak Solr Cloud aracılığıyla parçalanır (shard) ve kopyalanır (replica). Bu sayede uygun olarak yapılandırılmış bir koleksiyona bir kayıt eklediğinizde ilgili kaydın otomatik olarak herhangi Solr instance’ından birine dağıtımı sağlanır. Koleksiyonun bir parçası (shard) olan kaydın ilgili instance’lara aktarımı sayesinde okuma performansı artar. Ayrıca her doküman, yedek alınması için farklı bir instance’a kopyalanır (replica). Bu sayede herhangi bir Solr instance’ı çöktüğünde sadece cluster’ın toplam performansında bir azalma yaşanır fakat ilgili replica hâlâ diğer instance’larda bulunduğu için veri kaybı engellenmiş olur.
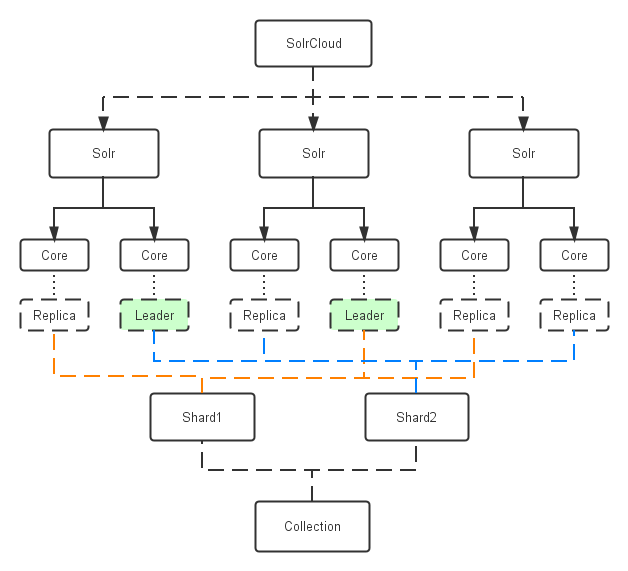
Shard, replica ve core arasındaki hiyerarşi — Görsel: linkedin.com
Bir cluster (küme) ise, her biri Solr çalıştıran bir JVM instance’ı olan düğümlerin (nodes) tamamından oluşan bir yapıdır. Bir node, birden fazla çekirdek (core) içerebilir. Core, bir shard’ın mantıksal olarak replica’sıdır. Genelde core’lar, koleksiyon adı, shard numarası ve replica numarasının birleşmesiyle oluşan bir string ile temsil edilirler.
Koleksiyon Oluşturma
REST-varî HTTP arayüzleriyle bir koleksiyon oluşturup yönetebileceğiniz gibi solr komutu ile de bu işlemi gerçekleştirebilirsiniz. Örnek veri olarak Data.gov adresinden sağlık gider verilerini indirebiliriz. Bize kolaylık sağlaması için CSV formatında export edelim. Daha önceden Solr oluşturduğumuz için aşağıdaki komutu kullanarak ipps (Inpatient Prospective Payment System) adında bir koleksiyon oluşturalım:
solr create_collection -d basic_configs -c ipps

Koleksiyonumuz hazır. İçerisine veri yüklemeden önce CSV dosyasında birkaç değişiklik yapalım. Öncelikle fiyat alanlarındaki tüm $ karakterlerini silelim. Ayrıca en üst satırdaki alan isimlerini aşağıdaki şekilde alt çizgi ile ayrılmış hale getirelim:
DRG_Definition,Provider_Id,Provider_Name,Provider_Street_Address,Provider_City,Provider_State,Provider_Zip_Code,Hospital_Referral_Region_Description,Total_Discharges,Average_Covered_Charges,Average_Total_Payments,Average_Medicare_Payments
Web’de Solr üzerinde çalışabilecek birçok ETL (Extract, Transform, Load) aracı bulmak mümkün, fakat bu şekilde de verilerimizi Solr’a aktarmak için bir ETL’e ihtiyaç duymadan kolayca hazır hale getirebilmiş olduk. Şimdi dosyayı ipps.csv adı altında C:\solr-6.6.0 dizini içerisine kaydedelim.
Verileri aktarmadan önce aynı geleneksel veritabanlarında olduğu gibi bir şema oluşturmamız gerekiyor. Postman’i kullanarak aşağıdaki şekilde bir istek gönderelim. Oluşturduğum ilgili collection’a bu adresten erişerek çalıştırabilirsiniz.
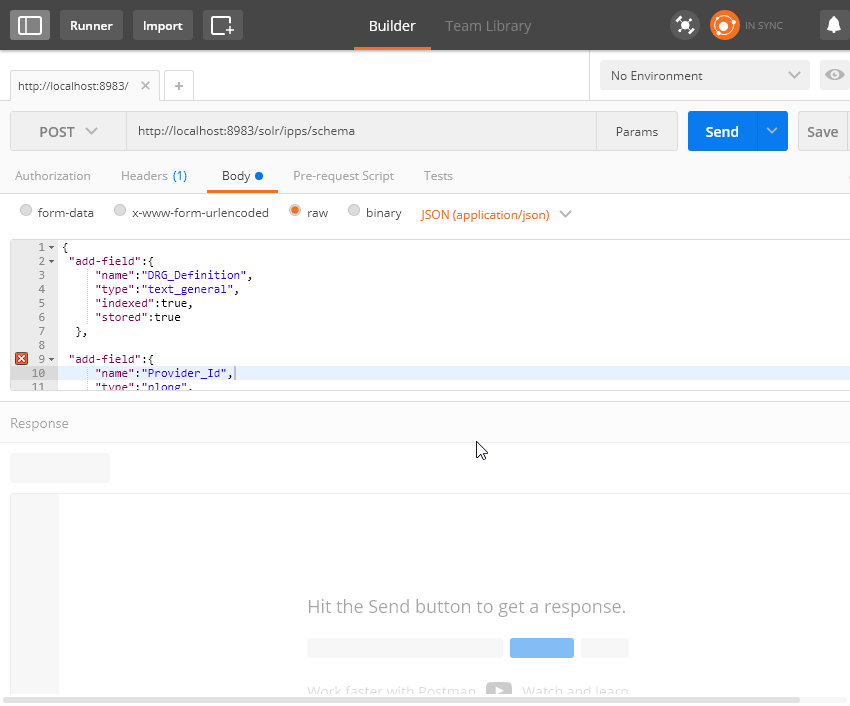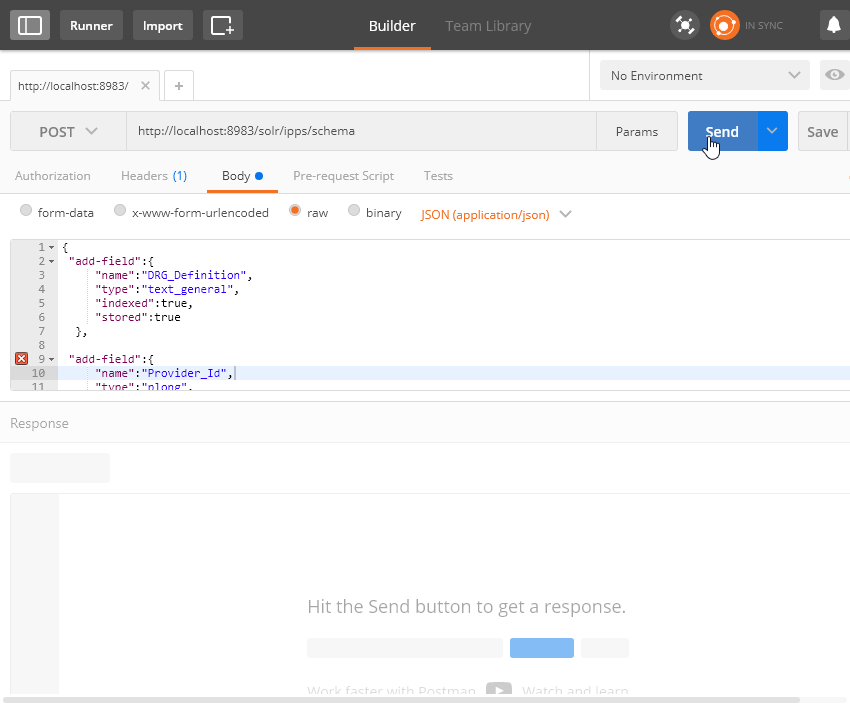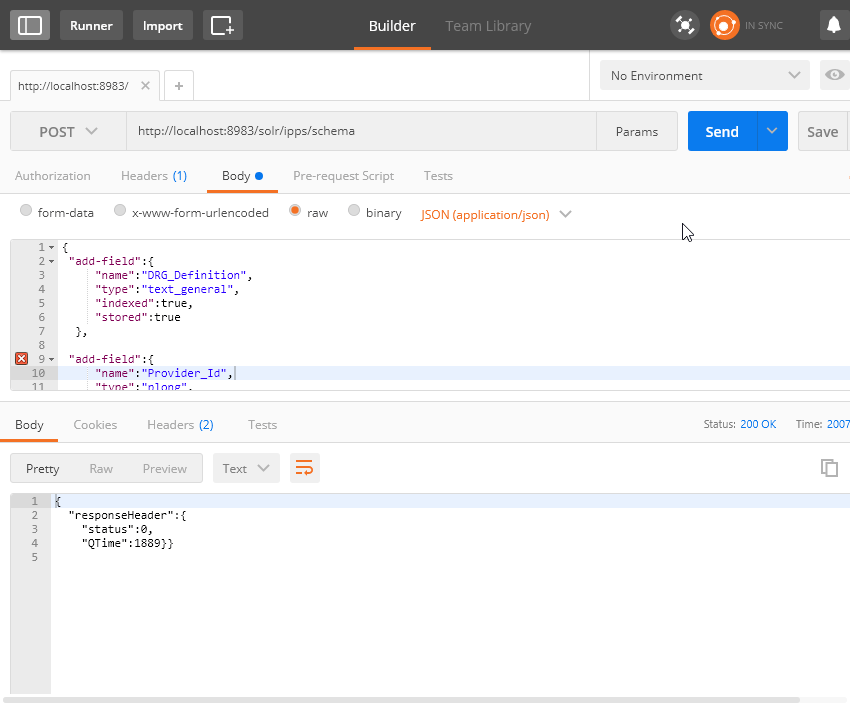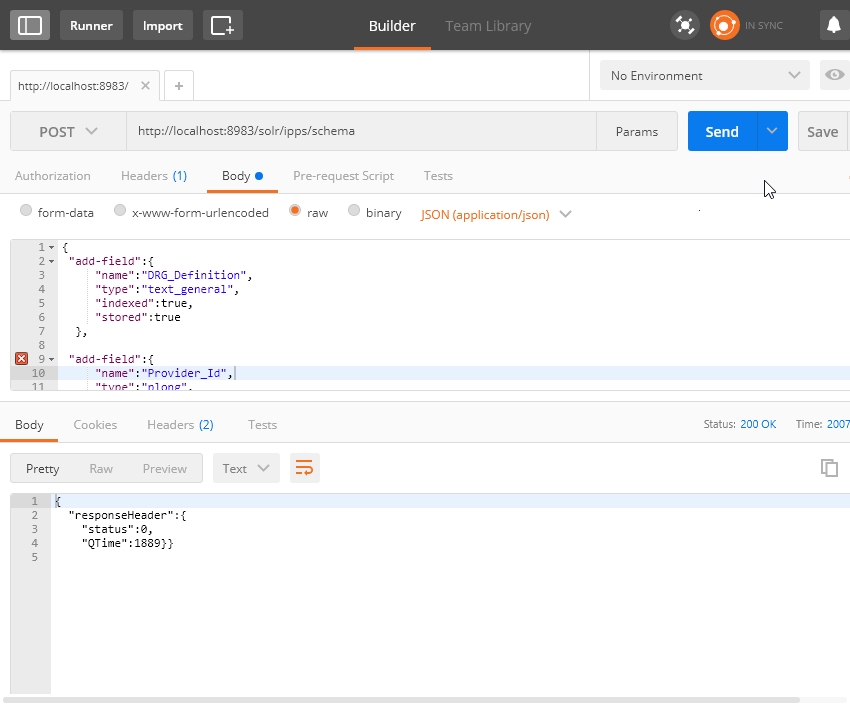
Başarılı bir şekilde oluştuğunda, ipps şeması üzerindeki fields elemanı altında eklediğiniz alanları görebilirsiniz.
Artık veri şemamızın da oluştuğuna göre verilerimizi Solr’a post etme vaktimiz de geldi demektir. Postman ile bu işi yapabileceğimiz gibi Linux ve MacOS ortamları için halihazırda bulunan bin/post CLI aracını da kullanabiliriz. Linux ve MacOS makine için:
bin/post -c ipps -params "rowid=id" -type "text/csv" ipps.csv
Windows için:
java -Dtype=text/csv -Dc=ipps -Dparams="rowid=id" -jar example\exampledocs\post.jar ipps.csv
Verilerimizi Solr’a atmış bulunuyoruz. Şimdi ise sorgular yazıp dönen sonuçları inceleyelim.
Verilerin Sorgulanması
Solr üzerinden sorgulamaların yapılabilmesi için .Net, Java ve Python dahil olmak üzere birçok programlama dili için destek verilmiş durumda. Bunun yerine direkt olarak tarayıcınızdan da sorgu işlemini gerçekleştirebilirsiniz. Şimdi aşağıdaki linki adres çubuğuna yapıştırıralım:
http://localhost:8983/solr/ipps/select?indent=on&q=Provider_Name:*ALABAMA*&wt=json
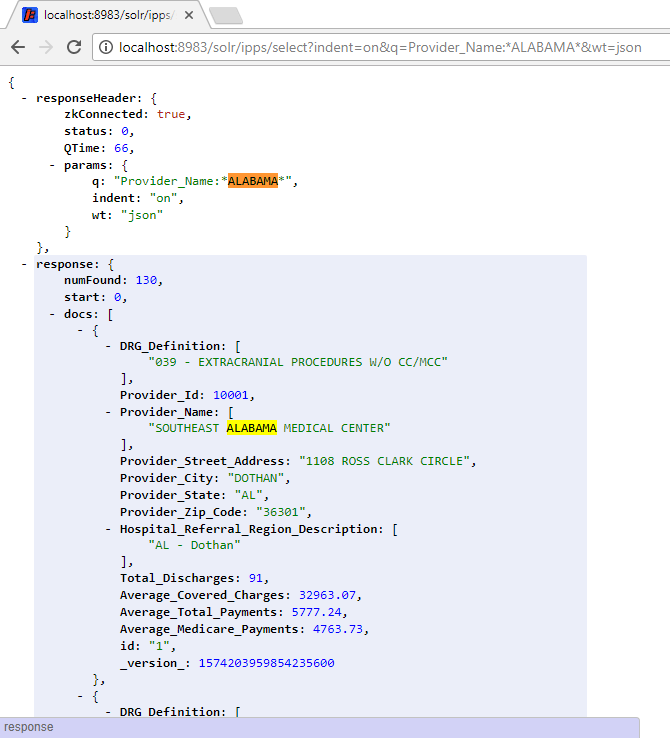
Adında “ALAMABA” bulunan hastane kayıtları
Üstteki sorgu, isminde ALABAMA yer alan hastanelerin kayıtlarının sorguyla en alakalı ilk 10 tanesini listeleyecektir. Sayfalamayı değiştirme ve Solr sorgulama dili ile ilgili bilgi için buradan erişebilirsiniz. Ayrıca JSON yerine XML çıktı üretmesini istiyorsanız wt=json alanını wt=xml olacak şekilde değiştirmeniz yeterli.
Solr Yönetimi
Eğer komut istemi üzerinden çalışmak istemiyorsanız Solr’ın ayrıca bir kullanıcı arabirimi de bulunmakta. http://localhost:8983/solr üzerinden girerek ilgili arabirime erişebilmeniz mümkün. Ayrıca eğer sol taraftan ipps koleksiyonunu seçerseniz hemen altındaki Query kısmına tıkladığınızda sorguyu girebileceğiniz güzel bir arayüz de bulunmakta:
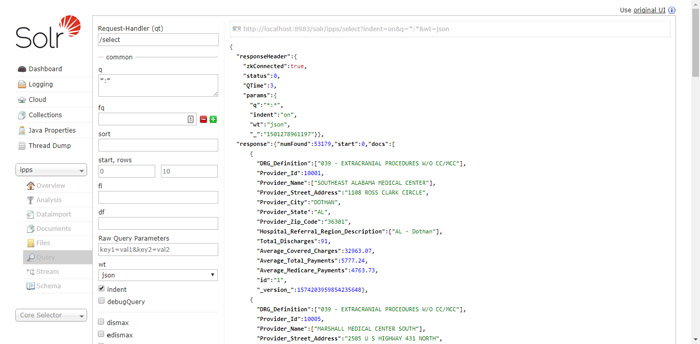
Bu girdiler kafamı çok karıştırıyor diyorsanız daha basitleştirilmiş bir sorgu ekranı bu linkte mevcut: http://localhost:8983/solr/ipps/browse
Basit metin sorguları gerçekleştirmiş olduk. Belirli aralıkları seçerek de aramanızın daha belirli bir alanda gerçekleşmesini sağlayabilirsiniz. Solr’ın varsayılan olarak ürettiği “alakalı sıralama” sizin için uygun değilse daha gelişmiş sorgu ifadeleri kullanarak aynı ilişkisel veritabanlarında olduğu gibi sadece sorguya uyan kayıtların getirilmesini sağlayabilirsiniz. Çeşitli alanları sıralayabilir, kategori bazlı filtreleme gerçekleştirebilirsiniz. Bununla da yetinmem diyorsanız Solr’ın learn to rank adındaki makine öğrenmesi yeteneklerinden faydalanarak Solr’ın sizin için en uygun sonucu öğrenmesini sağlayabilirsiniz.
Peki Neden Solr Kullanmalıyım?
Eğer bir arama motoruna ihtiyacınız varsa Solr kullanmak oldukça mantıklı görünüyor. Ayrıca Tableau gibi veri görselleştirme araçlarına bağlanmak için SQL sunan dağıtık bir doküman veritabanı da sağlamış oluyor. Birçok programlama dili ile Solr arasında iletişim kurabileceğiniz gibi JSON ve XML dokümanlarıyla da kolayca Solr ile etkileşimde bulunabilirsiniz.
Eğer küçük boyutlu bir veri ile uğraşıyorsanız ve key-value gibi bir yapınız varsa Solr sizin için pek uygun olmayabilir. Çünkü Solr büyük miktarda verinin hızlı bir şekilde işleneiblmesi için özelleşmiştir ve az boyutlu veri için anlamsız olacaktır.
Eğer arama kriterleriniz oldukça metin bazlı ise Solr sizin için vazgeçilmez bir seçenektir diyebiliriz. Bununla birlikte mekansal arama işlemlerinde de Solr oldukça elverişli sorgu bileşenleri sunmaktadır.
Bu yazımızda da arama işlemlerinde kullanabileceğiniz Apache Solr tanıtmaya çalıştık. Solr hakkındaki düşüncelerinizi aşağıdaki yorum kısmında bizimle paylaşabilirsiniz. Bir başka yazıda görüşmek üzere.


1 Comment
Mehmet
18 Şubat 2018 at 14:28Harika bir yazı olmuş. Elinize sağlık.